Работа с отказоустойчивой системой хранения данных NFS
Остановка кластеров СХД NFS
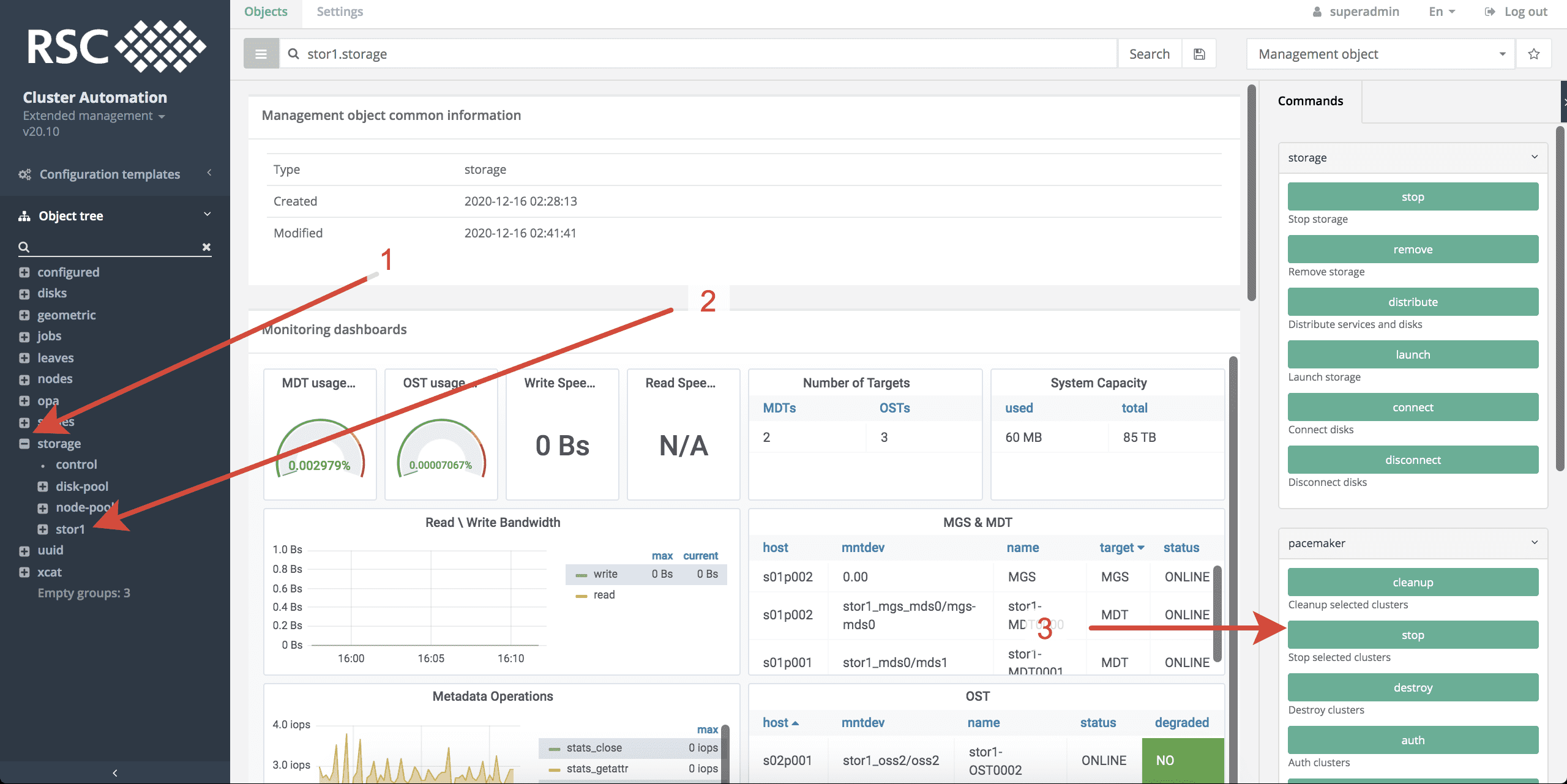
Для остановка кластеров СХД NFS необходимо выполнить следующие действия в системе мониторинга и управления РСК БазИС 4 (см. рисунки, приведенные ниже):
- Открыть топологию storage.
- Выбрать СХД NFS, нажав на её название, но не раскрывая данный объект.
- Запустить команду stop в группе команд pacemaker.
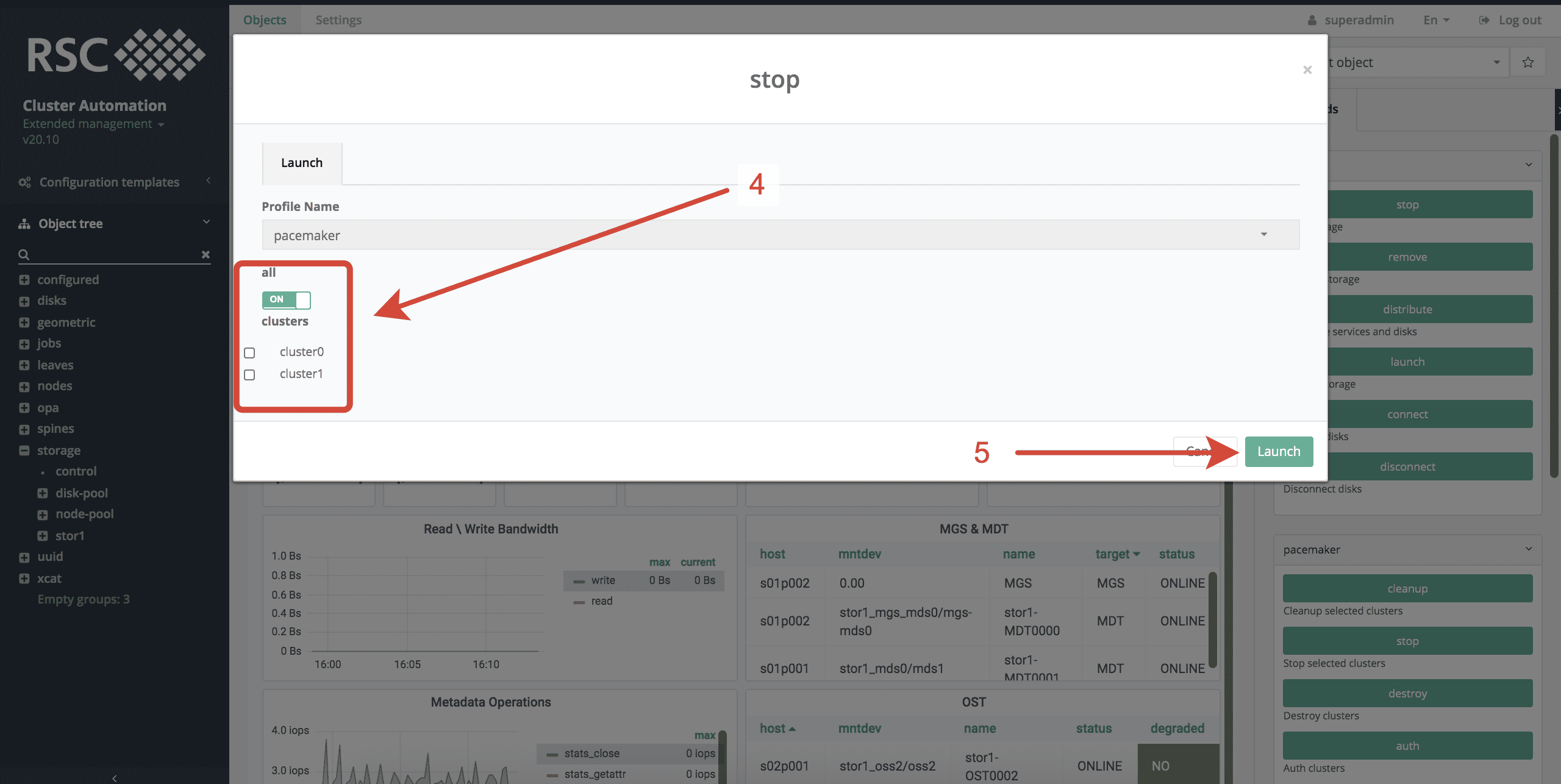
- Выберать все или определенные кластеры СХД NFS, которые необходимо остановить.
- Запустить процесс остановки кластеров СХД NFS, нажав Launch.1
Замена дисков в рейде
Замена дисков в рейд массиве происходит вруную. Диск можно заменить на диск равного или большего размера, находящийся в этой же группе заменяемого. Поэтому перед заменой надо убедиться, что запасные диски есть в этой группе. Это можно увидеть в профиле группы disk-pool в значении атрибута free. При необходимости заменить диск в рейд массиве нужно выполнить следующие действия:
- Выбрать группу дисков в топологии disk-pool.storage .
- Выполнить команду Edit и ввести новый QDSL для группы дисков (опционально: если нужно добавить диски в группу).
- Выполнить команду Replace. Выбрать заменяемый диск и диск на который необходимо провести замену.
Отключение узлов СХД NFS для проведения технических работ
При необходимости вывести узел СХД NFS из состава кластера можно либо остановить СХД NFS (см. раздел "Остановка кластеров и СХД"), в состав которой входит необходимый узел, либо выполнить следующую команду:
# на любом узле кластера СХД NFS
pcs node stanbdy <nodename>
Из кластера можно вывести число узлов не более уровня отказоустойчивости СХД NFS. Если на узле находились диски, используемые в самой СХД NFS, то при отключении узла эти диски пропадут из RAID-массивов на других узлах. Будьте внимательны!
Уничтожение СХД NFS
Процесс уничтожения СХД NFS состоит из двух этапов: - уничтожение кластеров СХД NFS (см. пп. 1-5); - удаление сведений о СХД NFS из топологии storage (см. пп. 6-9).
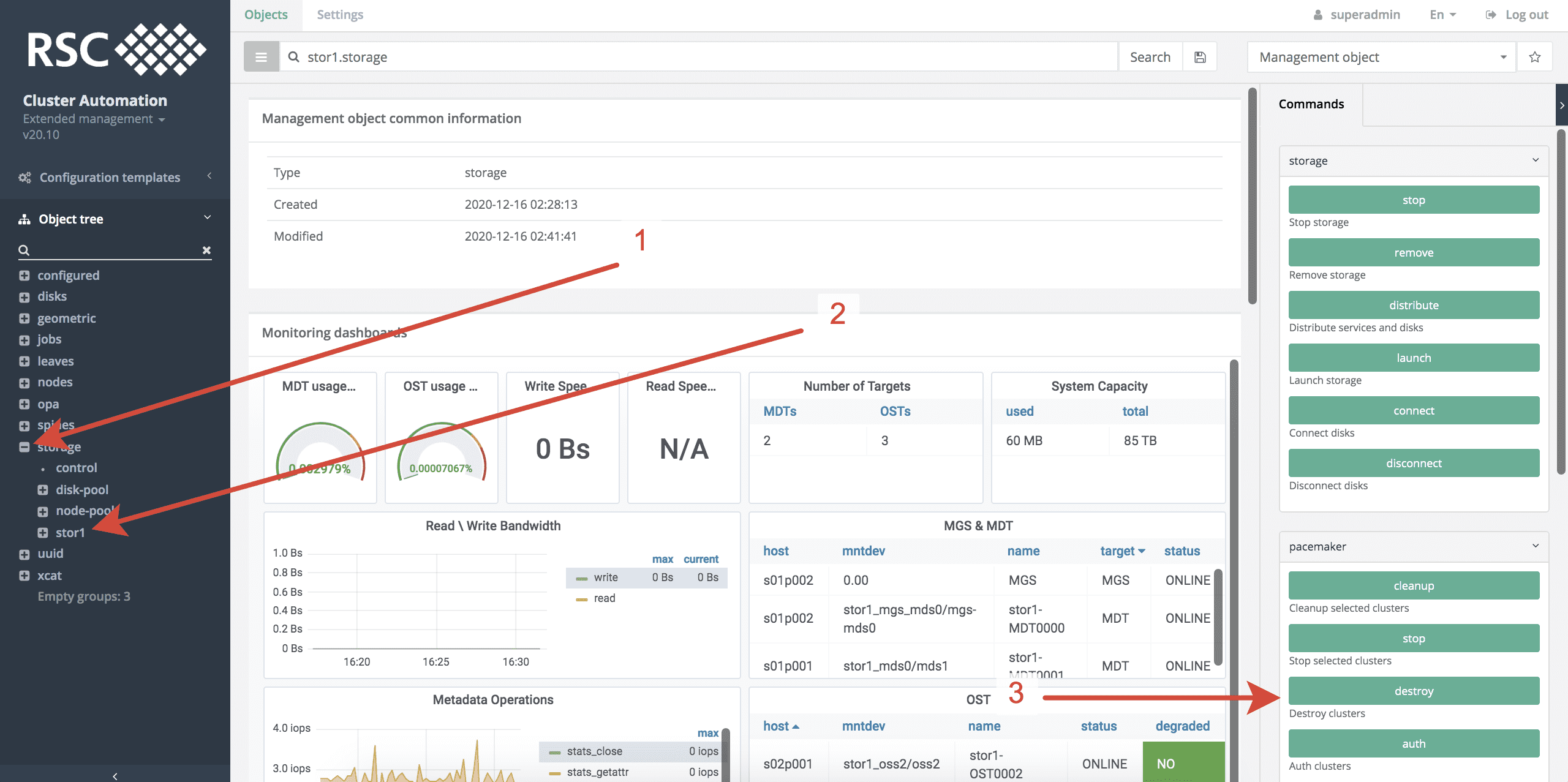
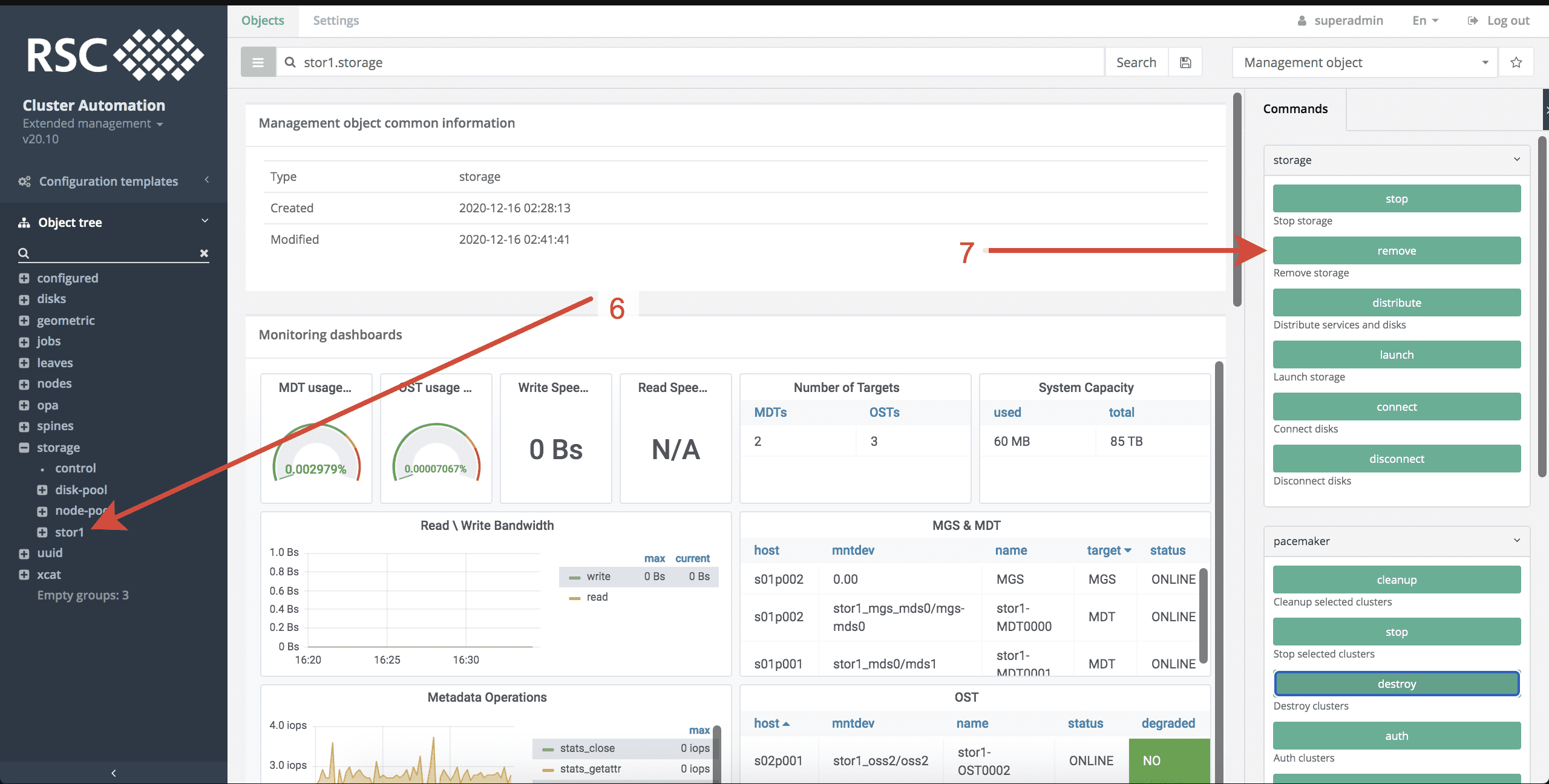
Для уничтожения СХД NFS необходимо выполнить следующие действия в системе мониторинга и управления РСК БазИС 4 (см. рисунки, приведенные ниже):
- Открыть топологию storage.
- Выбрать СХД NFS, нажав на её название, но не раскрывая данный объект.
- Запустить команду destroy в группе команд pacemaker.
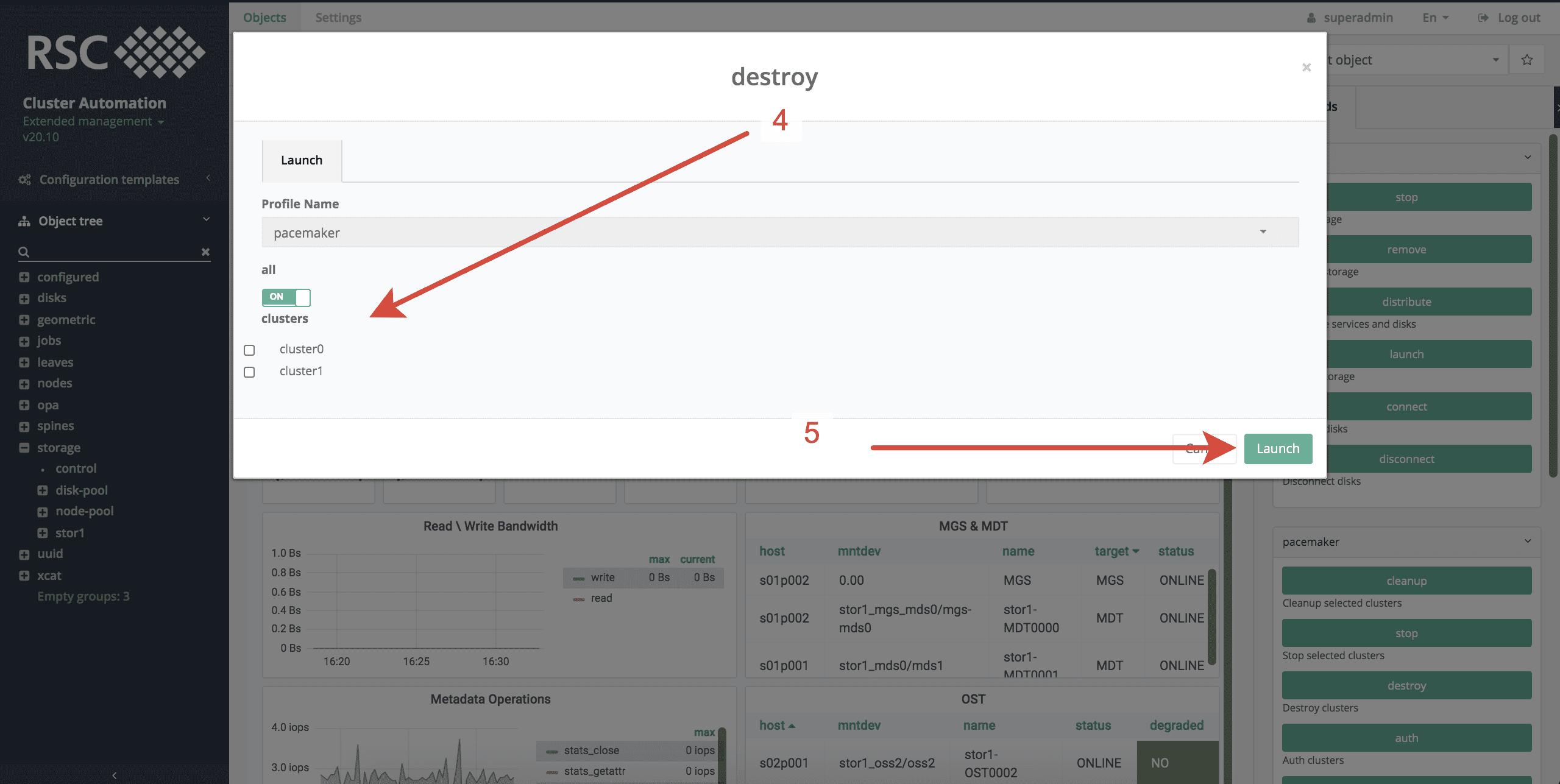
- Выбрать все или некоторые кластеры, которые необходимо уничтожить.
- Запустить процесс уничтожения СХД NFS, нажав Launch.2
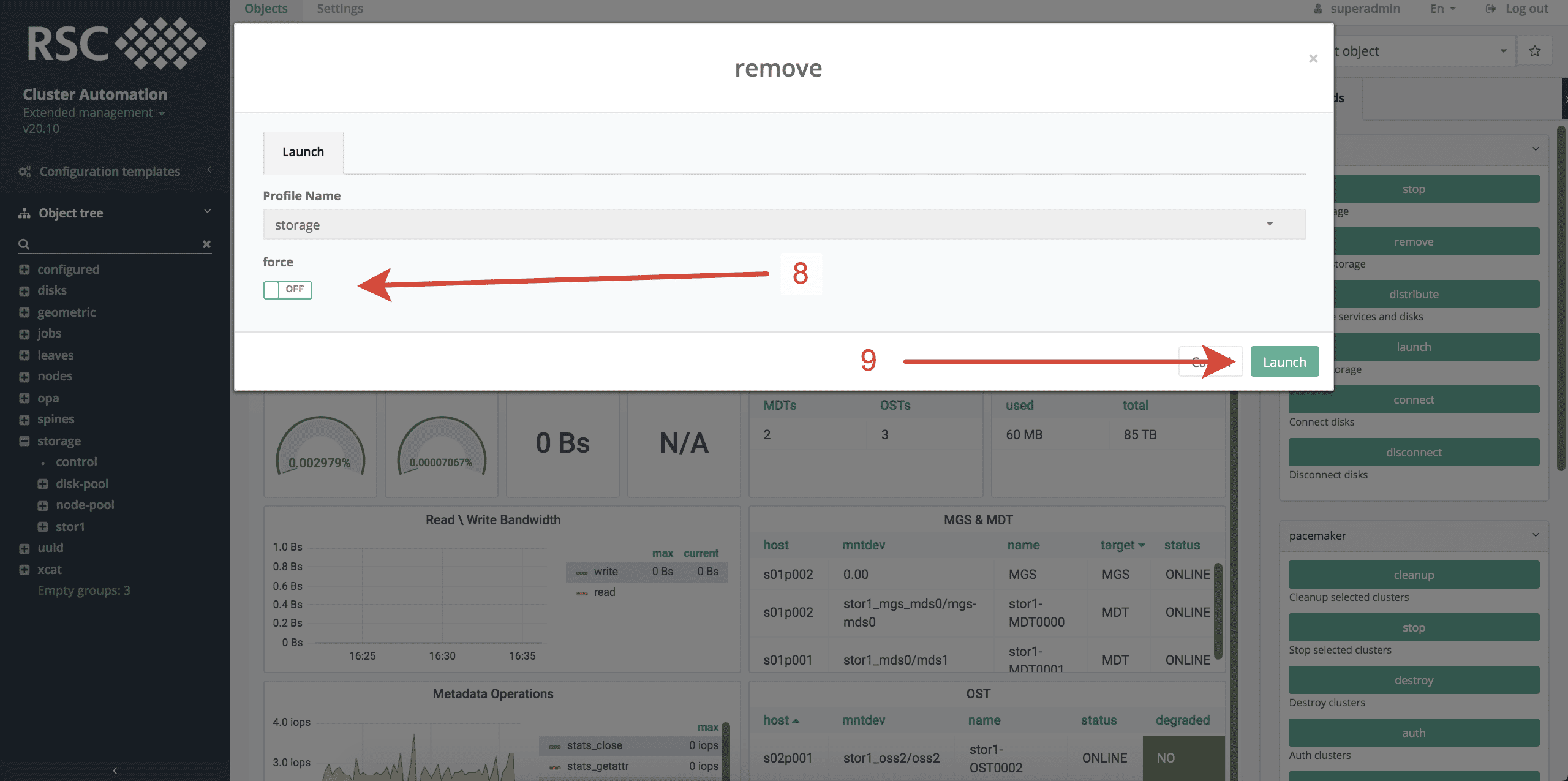
- Выбрать СХД, нажав на название уничтоженной СХД NFS, но не раскрывая данный объект.
- Запустить команду remove в группе команд storage.
- Выставить флаг force в значение on/off, в зависимости от того, надо ли учитывать состояние СХД NFS в топологии storage.
- Запустить процесс удаления сведений о СХД NFS из топологии storage, нажав Launch.
Часто используемые команды для работы с существующей СХД NFS
-
Посмотреть текущее состояние отказоустойчивого кластера СХД NFS:
pcs status -
Вернуть диски/RAID/сервисы в исходное состояние:
pcs resource cleanup -
Вернуть состояние RAID-массивов в режим ONLINE, если все диски на месте:
zpool clear -nFX <poolname> -
Вывести узел из состава кластера СХД NFS:
pcs node standby <nodename> -
Вернуть узел обратно в состав кластера СХД NFS:
pcs node unstandby <nodename> -
При зависании утилиты zpool/zfs необходимо выполнить перезагрузку всех узлов кластера с помощью утилиты rpower. Явным признаком такого состояния узлов хранения является индикация статусов RAID-массивов как FAILED (Blocked).
rpower <storagenodes> off rpower <storagenodes> on # on cluster's node pcs cluster start --all -
Сохранение конфигурационного файла pacemaker
pcs cluster cib > cluster_config.xml