Особенности реализации отказоустойчивых кластеров при использовании технологии NVMeOF
Общепринятым при создании СХД типа Lustre является использование в качестве "строительных блоков" т. н. отказоустойчивых кластеров, HA-кластеров, составленных из нескольких узлов хранения данных (минимум из двух), внутри которых размещаются жесткие диски, организованные в программные (или аппаратные) RAID-массивы1.
Однако при использовании в СХД технологии NVMeOF, которая позволяет без существенных потерь производительности в передаче данных составлять RAID-массивы из дисков, расположенных на разных узлах хранения данных, необходимо иметь в виду, что при отказе узлов HA-кластера могут возникать неожиданные побочные эффекты, связанные с особенностями работы RAID-массивов. При этом возможны две ситуации.
- Если сервисы СХД, запущенные на узлах отказоустойчивого кластера, осуществляют управление данными, физически расположенными на дисках RAID-массива с узлов ВНЕ HA-кластера, то при отказе одного из узлов HA-кластера произойдет переподключение этих дисков на сервисы, запущенные на соседних узлах HA-кластера, и тем самым СХД сможет продолжить работу с теми же самыми дисками RAID-массива, которые были доступны до отказа узла HA-кластера.
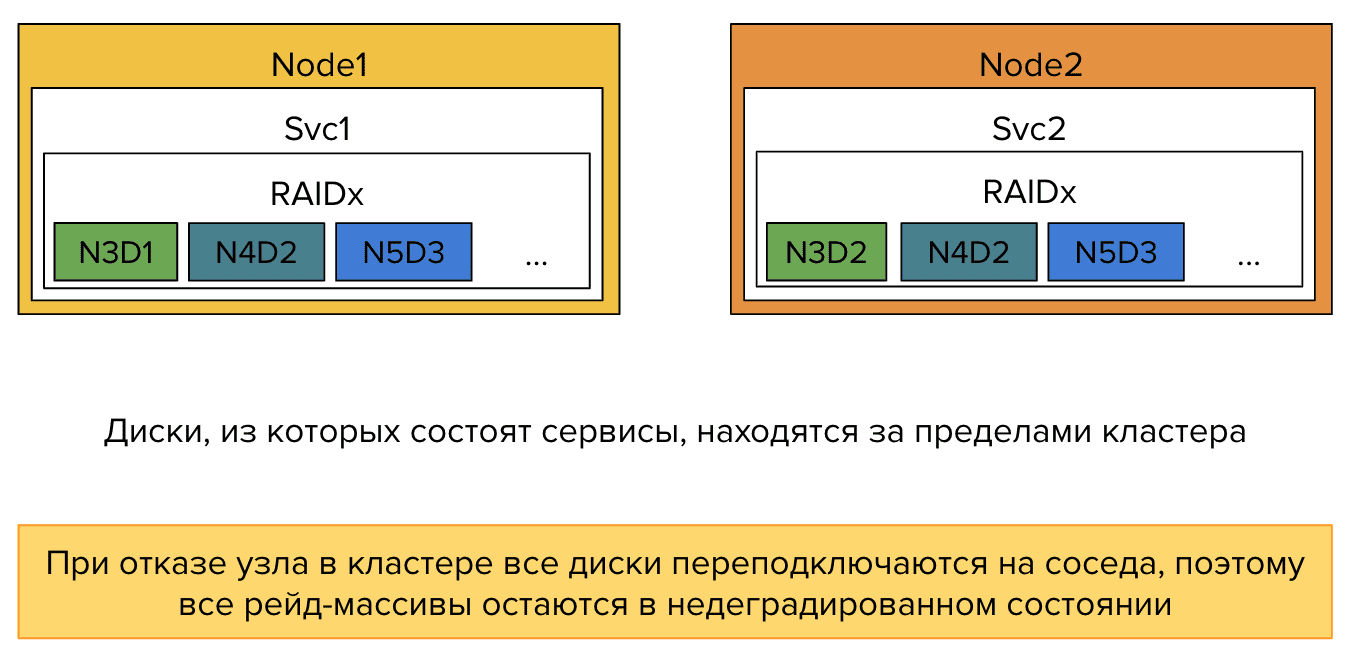
- Если для хранения данных используются диски с узлов ВНУТРИ HA-кластера, причем сами диски организованы в RAID-массивы по принципу разделения данных, согласно которому диски одного RAID-массива физически расположены на разных узлах HA-кластера, то при отказе одного из узлов HA-кластера пропадет доступ к его дискам для всех RAID-массивов, содержащих эти диски. Ниже приведена последовательность событий, происходящих при таком отказе.
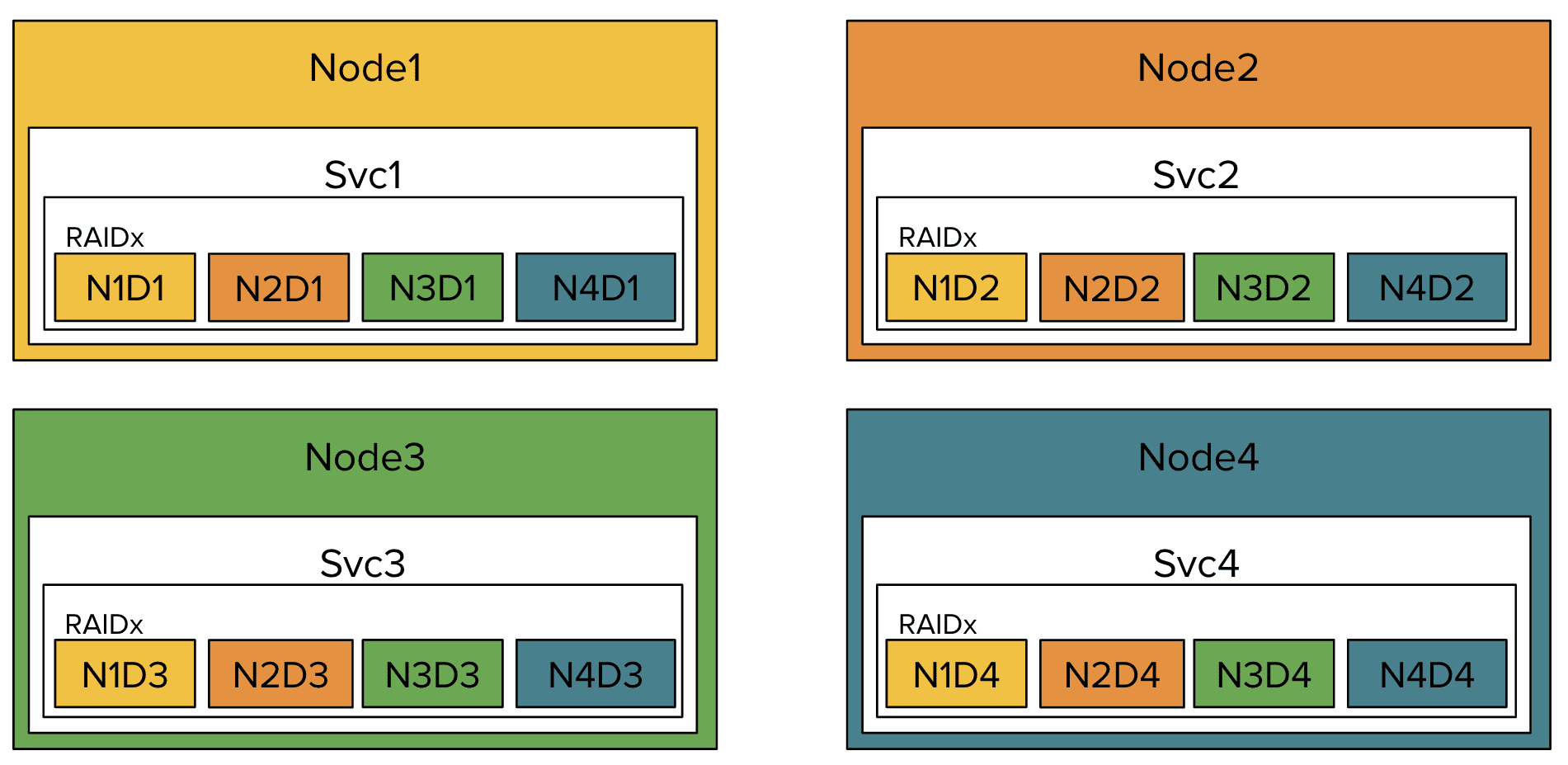
Предположим, например, что HA-кластер состоит из 4-х узлов, на каждом из которых расположено 4 диска. На каждом узле HA-кластера запущен сервис, использующий один таргет поверх RAID-массива.
Перед отказом
После отказа
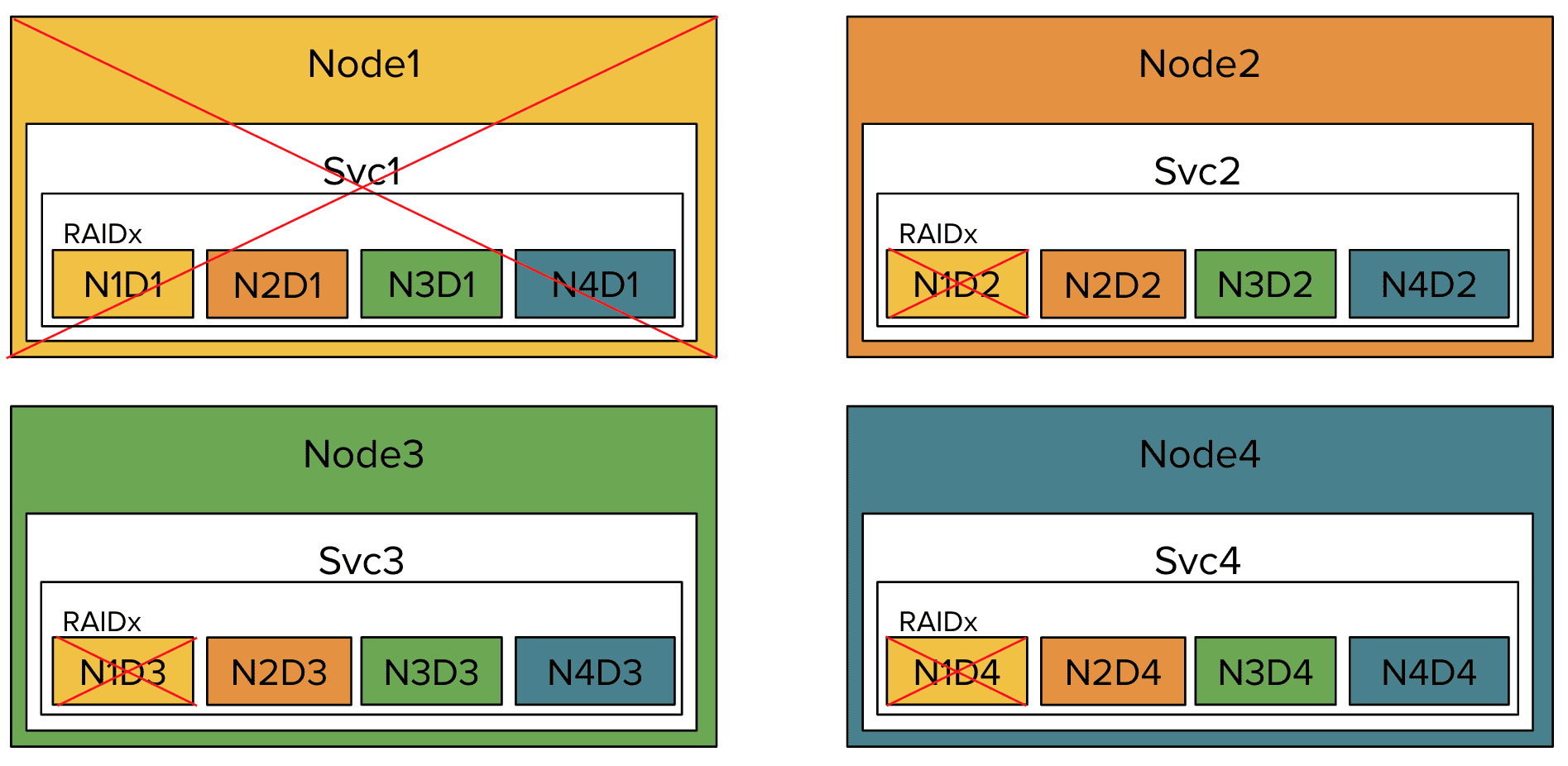
Если узел Node1 выходит из строя, то на других узлах пропадает доступ к дискам узла Node1: N1D2-N1D4.
Таким образом в зависимости от уровня организации RAID-массива и расположения его дисков по узлам хранения данных возможно возникновение ситуации полной потери данных. Для её предотвращения необходимо, чтобы т. н. уровень отказоустойчивости по узлам NRL HA-кластера был меньше или равен параметра избыточности по дискам для выбранного типа RAID-массива.2
-
(подобная схема хранения данных может быть применена и для СХД NFS, в тоже самое время СХД DAOS имеет свою собственную модель отказоустойчивости без использования RAID-массивов) ↩
-
(см., например, следующую таблицу сравнения RAID-массивов; если дисков в RAID-массиве меньше 8, то обычно используют RAID5 или RAID6, если дисков больше 8, то обычно используют групповые рейды RAID50 или RAID60.) ↩